Package: datasets
Each data frame has certain number of observations and variables
----------------------------------------------
#data frame airquality (154 obs and 6 variables)
require(graphics)
pairs(airquality, panel = panel.smooth, main = "airquality data")

#data frame BOD (6 rows and 2 columns)
require(stats)
# simplest form of fitting a first-order model to these data
fm1 <- nls(demand ~ A*(1-exp(-exp(lrc)*Time)), data = BOD,
start = c(A = 10, lrc = log(.30)))
coef(fm1)
fm1
# using the plinear algorithm
fm2 <- nls(demand ~ (1-exp(-exp(lrc)*Time)), data = BOD,
start = c(lrc = log(.30)), algorithm = "plinear", trace = TRUE)
# using a self-starting model
fm3 <- nls(demand ~ SSasympOrig(Time, A, lrc), data = BOD)
summary(fm3)
#data frame DNase (166 rows and 3 columns)
require(stats); require(graphics)
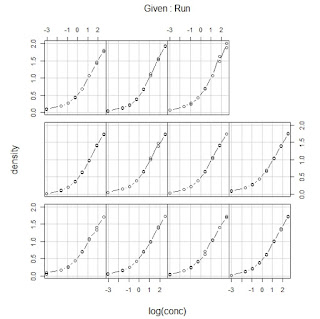
coplot(density ~ conc | Run, data = DNase,
show.given = FALSE, type = "b")
coplot(density ~ log(conc) | Run, data = DNase,
show.given = FALSE, type = "b")
## fit a representative run
fm1 <- nls(density ~ SSlogis( log(conc), Asym, xmid, scal ),
data = DNase, subset = Run == 1)
## compare with a four-parameter logistic
fm2 <- nls(density ~ SSfpl( log(conc), A, B, xmid, scal ),
data = DNase, subset = Run == 1)
summary(fm2)
anova(fm1, fm2)
 #data frame states (Facts of USA states)
#data frame states (Facts of USA states)
state.abb
state.area
state.center
state.division
state.name
state.region
state.x77
-------------------------------------------------------
Data frames can be very big, in millions of rows and columns and thousands of groups.
data.table, plyr is not an in-built, but additional package to handle such big data.
datasets is an inbuilt package with numerous data sets (A-Z, great for practice.
e.g. airquality, mtcars, trees, rivers, iris, volcano, quakes, states
Moidified from https://stat.ethz.ch/R-manual/R-devel/library/datasets/Each data frame has certain number of observations and variables
----------------------------------------------
#data frame airquality (154 obs and 6 variables)
require(graphics)
pairs(airquality, panel = panel.smooth, main = "airquality data")

#data frame BOD (6 rows and 2 columns)
require(stats)
# simplest form of fitting a first-order model to these data
fm1 <- nls(demand ~ A*(1-exp(-exp(lrc)*Time)), data = BOD,
start = c(A = 10, lrc = log(.30)))
coef(fm1)
fm1
# using the plinear algorithm
fm2 <- nls(demand ~ (1-exp(-exp(lrc)*Time)), data = BOD,
start = c(lrc = log(.30)), algorithm = "plinear", trace = TRUE)
# using a self-starting model
fm3 <- nls(demand ~ SSasympOrig(Time, A, lrc), data = BOD)
summary(fm3)
#data frame DNase (166 rows and 3 columns)
require(stats); require(graphics)
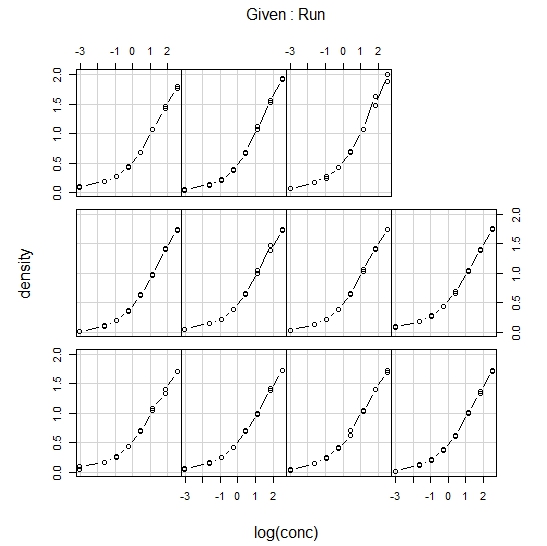
coplot(density ~ conc | Run, data = DNase,
show.given = FALSE, type = "b")
coplot(density ~ log(conc) | Run, data = DNase,
show.given = FALSE, type = "b")
## fit a representative run
fm1 <- nls(density ~ SSlogis( log(conc), Asym, xmid, scal ),
data = DNase, subset = Run == 1)
## compare with a four-parameter logistic
fm2 <- nls(density ~ SSfpl( log(conc), A, B, xmid, scal ),
data = DNase, subset = Run == 1)
summary(fm2)
anova(fm1, fm2)
state.abb
state.area
state.center
state.division
state.name
state.region
state.x77
-------------------------------------------------------
Data frames can be very big, in millions of rows and columns and thousands of groups.
data.table, plyr is not an in-built, but additional package to handle such big data.
No comments:
Post a Comment